About PARAM Rudra
PARAM Rudra, a cutting-edge supercomputing facility, was established under Phase-3 of the National Supercomputing Mission's build approach. It boasts a peak computing power of 838 TFLOPS and was designed and commissioned by C-DAC to meet the computational needs of IIT,Patna and various research and engineering institutes in the region. The system is valuable for research in various scientific domains, including materials science, earth science, chemical and biological sciences, high energy physics, cosmology and astrophysics and more.
| System Specifications | |
|---|---|
| Theoretical Peak Floating-point Performance Total (Rpeak) | 838 TFLOPS |
| Base Specifications (Compute Nodes) | 2X Intel Xeon GOLD 6240R, 24 Cores, 2.4 GHz Processors per node, 192 GB Memory, 800 GB SSD |
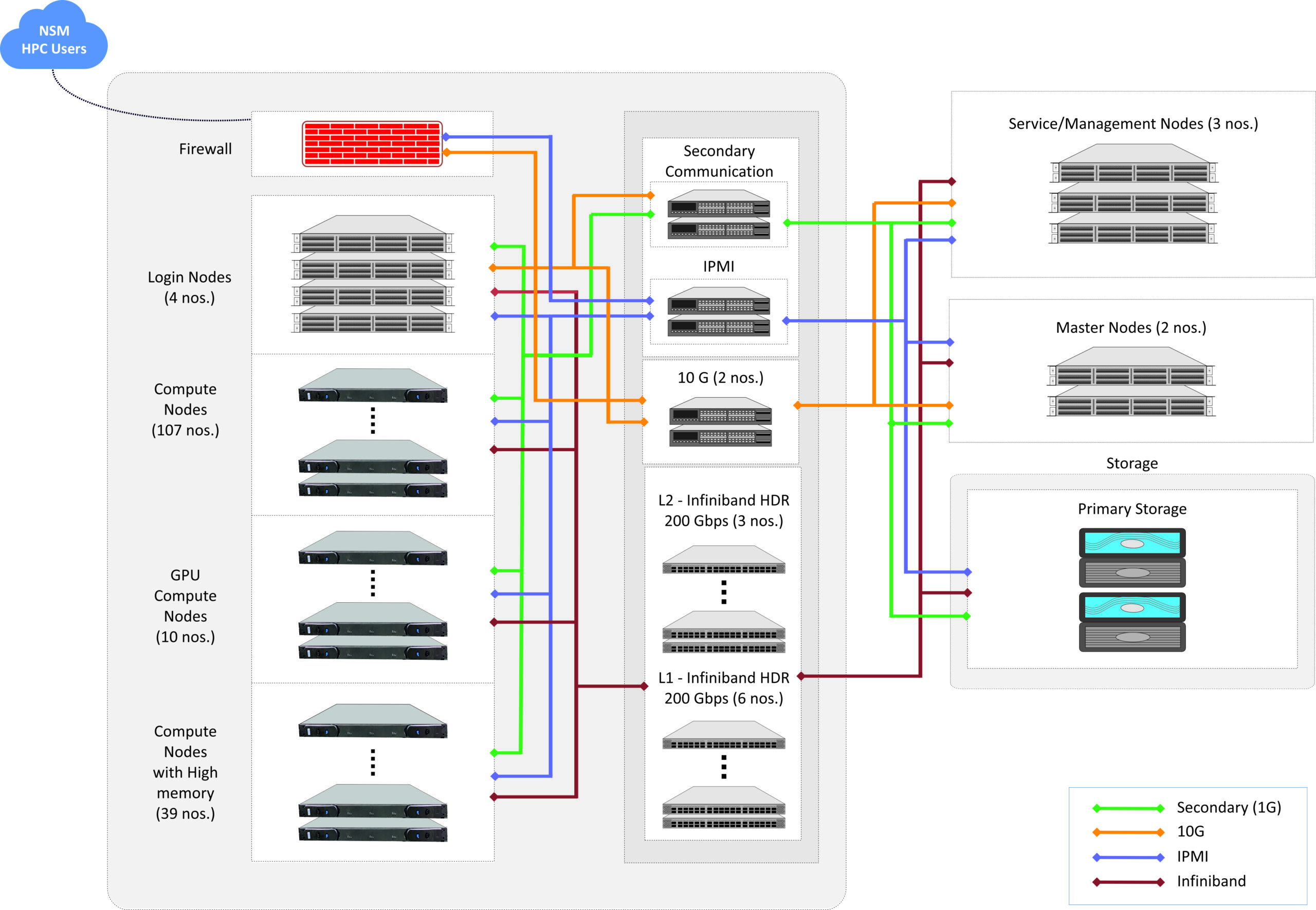
| Master/Service/Login Nodes | 10 nos. |
| CPU only Compute Nodes (Memory) | 96 nos. (192GB) |
| GPU Ready Nodes (Memory) | 26 nos. (192GB) |
| High Memory Compute Nodes | 32 nos. (768GB) |
| Total Memory | 49.536 TB |
| Interconnect | Primary: 100Gbps Mellanox Infiniband Interconnect Network 100% non-blocking, fat tree topology Secondary: 10G/1G Ethernet Network Management Network: 1G Ethernet |
| Storage | 1.0 PiB |
| CPU Only Compute Nodes | |
|---|---|
| Nodes | 96 |
| Cores | 4608 |
| Compute Power of Rpeak | 353.89 TFLOPS |
| Each Node with | 2 X Intel Xeon GOLD 6240R,
24 Cores, 2.4 GHz 192 GB memory 800 GB SSD |
| GPU Only Compute Nodes | |
|---|---|
| Nodes | 8 |
| CPU Cores | 384 |
| Rpeak | 275.81 TFLOP |
| Each Node with | 2 X Intel Xeon GOLD 6240R,
24 cores, 2.4 GHz 192 GB Memory 2 x NVIDIA A100 800 GB SSD |
| High Memory Compute Nodes | |
|---|---|
| Nodes | 32 |
| CPU Cores | 1536 |
| Compute Power of Rpeak | 117.964 TFLOPS |
| Each Node with | 2 X Intel Xeon GOLD 6240R,
24 cores, 2.4 GHz 768 GB Memory 800 GB SSD |
| GPU Ready Nodes | |
|---|---|
| Nodes | 26 |
| CPU Cores | 1248 |
| Rpeak | 95.846 TFLOP |
| Each Node with | 2 X Intel Xeon GOLD 6240R,
24 cores, 2.4 GHz 192 GB Memory 2 x NVIDIA A100 800 GB SSD |
PARAM Rudra Details
Architecture Diagram:

Software Stack:

Installed Applications/Libraries
HPC Applications
- Bio-informatics: MUMmer, HMMER, MEME, PHYLIP, mpiBLAST, ClustalW
- Molecular Dynamics: NAMD (for CPU and GPU), LAMMPS, GROMACS
- CFD: OpenFOAM, SU2
- Material Modeling, Quantum Chemistry: Quantum-Espresso, Abinit, CP2K, NWChem
- Weather, Ocean, Climate: WRF-ARW, WPS (WRF), ARWPost (WRF), RegCM, MOM, ROMS
Deep Learning Libraries
- cuDNN, TensorFlow, Theano
Dependency Libraries
- NetCDF, PNETCDF, Jasper, HDF5, Tcl, Boost, FFTW
Support
For any support, contact: rudrasupport@iitp.ac.in
PARAM Rudra Usage Report
Link To Be Added
*Note: The above data is coming from C-Chakshu (Multi Cluster Monitoring Platform)